[Zoom Recording] – [Website and Slides] – [Proposal] – [Q&A] – [Backup Recording]
- This tutorial is given by Akari Asai, Sewon Min, Zexuan Zhong, and Danqi Chen
Contents
Overview
RALM is an LM that uses external databases in the test time.
The motivation of RALM is the pessimism about the current editing-based approaches. If we are able to edit the LLMs as fast as CRUD operations on databases, the retrieval-based approaches and editing-based approaches are comparable.
Moreover, these parametric LMs are fundamentally incapable of adapting over time, often hallucinate, and may leak private data from the training corpus. […] Retrieval-based LMs can outperform LMs without retrieval by a large margin with much fewer parameters, can update their knowledge by replacing their retrieval corpora, and provide citations for users to easily verify and evaluate the predictions.
Besides ease of updating knowledge, the retrieval-based approaches also have following advantages:
- Traceability, Verifiability, Interpretability, and Controllability: They mean the same thing for RALMs.
- Privacy and Copyright: The LMs are only responsible for making inference. The more relevant documents are stored in the databases.
There are some use cases where the RALMs are most suitable:
- Long-tail: For example, “Where is the Toronto zoo located?”
- Knowledge Update: For example, “what is the population of Toronto metropolitan area in 2000?”
- Verifiability, Factuality, and Hallucination
- Parameter-Efficiency: RALMs could improve performance of smaller LMs and make them competitive with larger ones.
- Parameter Update: We do not have to update the model itself when we could update the database.
- OOD Generalization
Architecture
Three elements of RALMs:
- What to Retrieve? What is the minimal unit for retrieval. The choices could be token, document, or text chunk.
- How to Use the Retrieval Results? Input, output, or somewhere in between?
- When to Retrieve? Only once, every token, or somewhere in between?
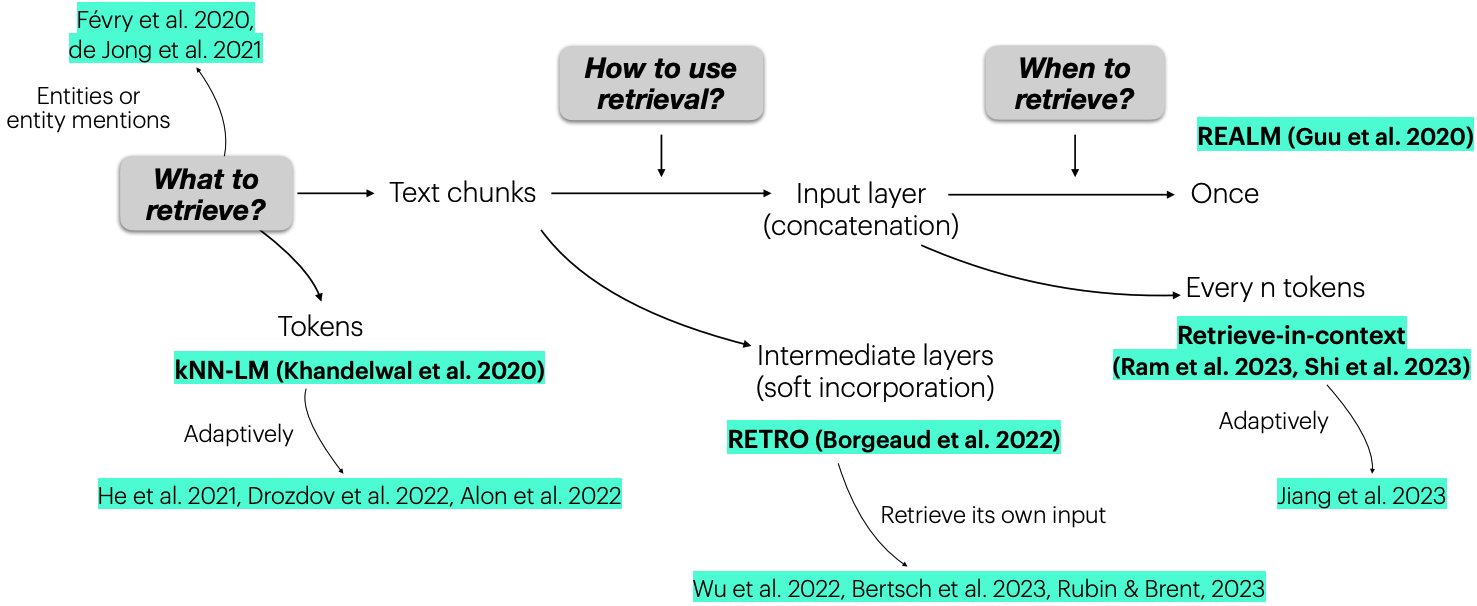
-
REALM is one of the first works in RALM. The goal is improving MLM LM pretraining. The followup papers include DPR, RAG, Atlas; they all focus on knowledge intensive tasks:
- DPR
- RAG
- Atlas
-
Retrieval-in-context LM
- REPLUG: The prompt is used to retrieved a set of documents; these documents are then prepended to the prompt and form an ensemble to predict the new tokens.
-
Ram et al.: We do not have to use the entire prompt as query. It may be better to use more recent tokens (due to higher relevance to the tokens to generate) as long as they are not too short.
Further, we may want to retrieve more often. For example, after we have already generated some tokens, it is time to retrieve again for the next batch of new tokens.
-
RETRO
- Used in the intermediate layer. Specifically, each prompt is chunked into multiple pieces and sent to retrieve some results; these results are sent into the LM through a specially design attention mechanism. The authors also consider some parallelization techniques for the sake of efficiency.
- Another orthogonal finding of this paper is that the scale of the datastores are important.
-
kNN-LM
- Using the test prefix to query for the prefixes that are already continued with new tokens. The token to generate will be an linear interpolation between the actual generated new tokens and the new tokens that belong to the best match prefix.
-
The motivation of this design is that the text representations of the entire sentences could be quite different even though the same word appears in it. For example, the word “torch” and “cheap.”
Comment: The motivation of this design is dubious. Furthermore, the interaction between the input and the retrieved results is limited.
-
Extensions to kNN-LM
- Adaptive Retrieval. Whether the retrieval is enabled depends on the confidence of the outputs. For example,
- FLARE and He et al. More specifically, the \lambda in kNN-LM could be a function of confidence.
- Alon et al.
- Adaptive Retrieval. Whether the retrieval is enabled depends on the confidence of the outputs. For example,
-
Entities as Experts
- Entities could be represented as dense vectors and incorporated into the intermediate layers of a model.
- Extension: Mention Memory
| Paper | What | When | How | Note |
|---|---|---|---|---|
| REALM | Chunks | Once | Input | Used in real-world applications such as you.com, Bing Chat, and perplexity.ai. |
| Retrieve-In-Context LM | Chunks | Every n Tokens | Input | Used in real-world applications such as you.com, Bing Chat, and perplexity.ai. |
| RETRO | Chunks | Every n Tokens | Intermediate | |
| kNN-LM | Tokens | Every Token | Output | |
| FLARE | Chunks | Adaptive | Input | |
| Adaptive kNN-LM (He et al., Alon et al.) | Tokens | Adaptive | Output | |
| Entities of Experts; Mention Memory | Entities or Entity Mentions | Every Entity Mention | Intermediate | |
| Wu et al., Bertsch et al., Rubin & Berant | Chunks from Input | Once or Every n Tokens | Intermediate | All methods above retrieve from external text. We can also retrieve from the book-length input. |
Training
We could update (1) the LM itself and (2) retrieval model. However, training either of them is difficult as (1) LM is typically large and therefore expensive to make parameter updates (2) index has to be updated every time we update the the encoder and this is proportional to the number of documents in the database.
There are 4 strategies for training the RALMs. Independent and sequential training render no or weak dependence between the LM and RM but the system performance is not as strong as the joint training (i.e., training the LM and RM jointly); the downside of the joint training is the requirement for a special training protocl.
Independent Training
Training LM and retrieval model independently. Each component could be improved separately; the improvement in each component will translate to the final improvement.
- LM
-
Retrieval Model: It could be BM25 or DPR. BM25 does not need explicit training and the training of DPR is pretty straightforward. Note that the loss used to promote the correct pairs from the in-batch negatives is a type of contrastive learning.
Besides DPR, another model is the contriver model (Izacard et al.), which is able to train in an unsupervised fashion.
Here are some examples of using this scheme:
- kNN-LM: The retrieval model is fixed and only the LM is trained.
- Ram et al.
Sequential Training
Sequential training means training one component first and then training the second component; the training of the second component depends the first component. As there are two components, we could either start from training the LM or the retrieval model.
- RM \rightarrow LM: For example, RETRO.
- LM \rightarrow RM: For example, REPLUG. Besides the ensemble prediction scheme, the authors further propose a method to fine-tune the retrieval model (dubbed as “LSR” by the authors) based on the feedback of the LM.
Joint Training with Asynchronous Index Update
Asynchronous index update means that we allow the index to “stale:” we do not reindex every document every time we update the encoder; rather, we only reindex the documents every T steps.
Joint Training with In-Batch Approximation
Applications
Questions
- Where should we use RALMs.
- Where should we plug in the RM + database.
- Should we update the LM or RM.
- What database should be used? Wikipedia, training data, or code documtation.
- WebGPT and GopherCIte uses the Google search results as data store.
| Task | Method | Database | |
|---|---|---|---|
| DocPrompt | Code Generation | Prompting (Input) Fine-Tuning LM |
Code Documentation |
| KNN-Prompt | Classification | Prompting (Output) | Wikipedia + CC |
| REPLUG | Knowledge-Intensive | Prompting (Input) | Wikipedia + CC |
| ATLAS | Knowledge-Intensive | Fine-Tuning LM and RM | Wikipedia + CC |
| GopherCite | QA | Fine-Tuning + RL on LM | Google Search Results |
Additional Notes
- The backup video is downloaded based on the instruction documented here. Basically, we just need to replace the
<cookie content>and<request url>with the content we obtain afterF5\rightarrowF12in the browser.
youtube-dl -o video.mp4 --referer "https://zoom.us/" --add-header "Cookie: COOKIE_CONTENT" 'REQUEST_URL'
Reference
- Building Scalable, Explainable, and Adaptive NLP Models with Retrieval | SAIL Blog
- Atlas: Few-shot Learning with Retrieval Augmented Language Models (Izacard et al., 2022)
- Teaching language models to support answers with verified quotes (Menick et al., 2022)
- REPLUG: Retrieval-Augmented Black-Box Language Models (Shi et al., 2023)
- kNN-Prompt: Nearest Neighbor Zero-Shot Inference (Shi et al., 2022)
- Attributed Question Answering: Evaluation and Modeling for Attributed Large Language Models (Bohnet et al., 2023)
- DocPrompting: Generating Code by Retrieving the Docs (Zhou et al., 2022)
- REALM: Retrieval-Augmented Language Model Pre-Training (Guu et al., 2020)
- In-Context Retrieval-Augmented Language Models (Ram et al., 2023)
- Improving language models by retrieving from trillions of tokens (Borgeaud et al., 2022)
- Generalization through Memorization: Nearest Neighbor Language Models (Khandelwal et al., 2020)