Note:
– The presenter of this talk is the lead author of the paper A Holistic Approach to Undesired Content Detection in the Real World.Change Logs:
- 2023-08-29: First draft.
Overview
There are two main iterations to build an end-to-end content moderator.
– Annotation Iteration: OpenAI outsource the most of the annotation iteration to external data providers. They also have internal expert annotators to provide the labels of the quality control set.
– Main Iteration: This is the bulk of the OpenAI’s contribution.
Annotation Iteration
- Labeling guidelines need to be clarified and updated multiple times with more and more edges surface. The specifications from OpenAI are finally turned into training materials of their label providers to educate their annotators.
- There should be sessions that
- Calibrating the annotators by clarifying the annotation guidelines.
- Auditing data that are flagged harmful either by the annotators or the model. Removing annotations from the annotator that has low per-category F1 scores. This process could be accelerated using cross-auditing with multiple annotators.
Main Iteration
There following are the diagrams that outline the steps above:
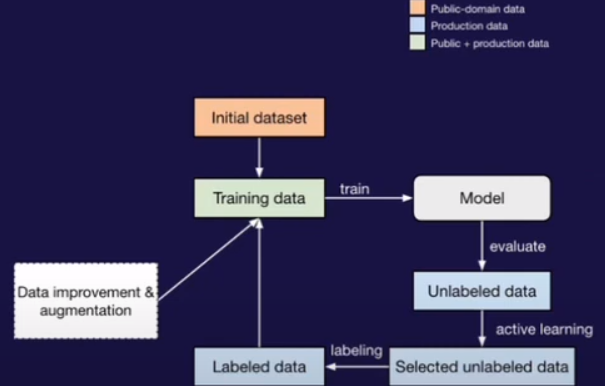
- Step 0: Creating an initial dataset. This initial dataset includes those from “bad” (and unlabeled) subset of CommonCrawl, expert selected academic dataset, and zero-shot synthetic data from GPT-3 based on hand-crafted templates.
- Step k-1: \cdots
- Step k: In the iteration k, training a model \mathcal{M}_k based on GPT-series model using the standard cross-entropy loss.
One of the things the OpenAI could not solve well is the calibration.
- Step k+1: Using \mathcal{M}_k to run inference on the unlabeled production data; the probabilities are used to select the subset for annotation. Three methods are compared:
- Purely Random Sampling
- Random Sampling for Samples Above a Threshold
- Uncertainty Sampling
Active learning substantially improves the ratio of harmful contents in the user traffic (10 – 22 times).
After the subset is annotated, it is added back to the training set. Further, there is also synthetic data that is added to address the counterfactual bias.
-
Step k+2: Running the following steps to further improve the training data.
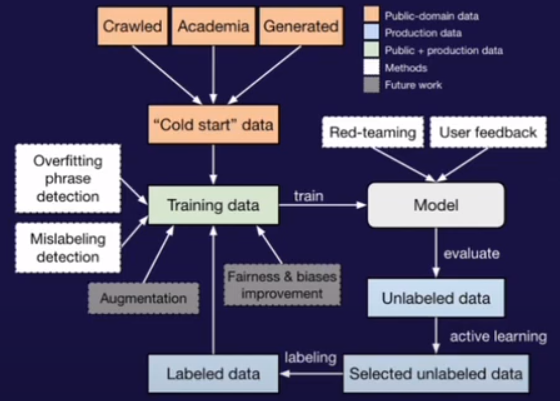
- Overfitted Phrase Detection.
- Mislabeling Detection.
- Step k+3: Internal red teaming.
- Step k+4: \cdots
- Step -3:
- Evaluating on the static test set.
- A/B testing.
- Step -1: Product release.
Here is a more detailed diagram; it is same as the one provided in the paper.
Future Direction
-
Dataset
- A more systematic approach to create synthetic dataset. The current approach OpenAI uses is described ad-hoc.
- Robustness to prompt injection and ciphers.
- Continuous GPT-Assisted Red Teaming
- Active Leraning
- The current active learning approach relies on the model \mathcal{M}_k at Step k+1, which the model \mathcal{M}_k may not be able to generalize.
- The presenter also mentions anomaly detection; it is not prioritized in OpenAI due to time constraint.