[Semantic Scholar] – [Code] – [Tweet] – [Video] – [Website] – [Slide] – [HuggingFace]
Change Logs:
- 2023-09-04: First draft. This paper appears at WOAH ’23. The provided models on HuggingFace have more than 40K downloads thanks to their easy-to-use
tweetnlp package; the best-performing binary and multi-class classification models are cardiffnlp/twitter-roberta-base-hate-latest and cardiffnlp/twitter-roberta-base-hate-multiclass-latest respectively.
Method
Datasets
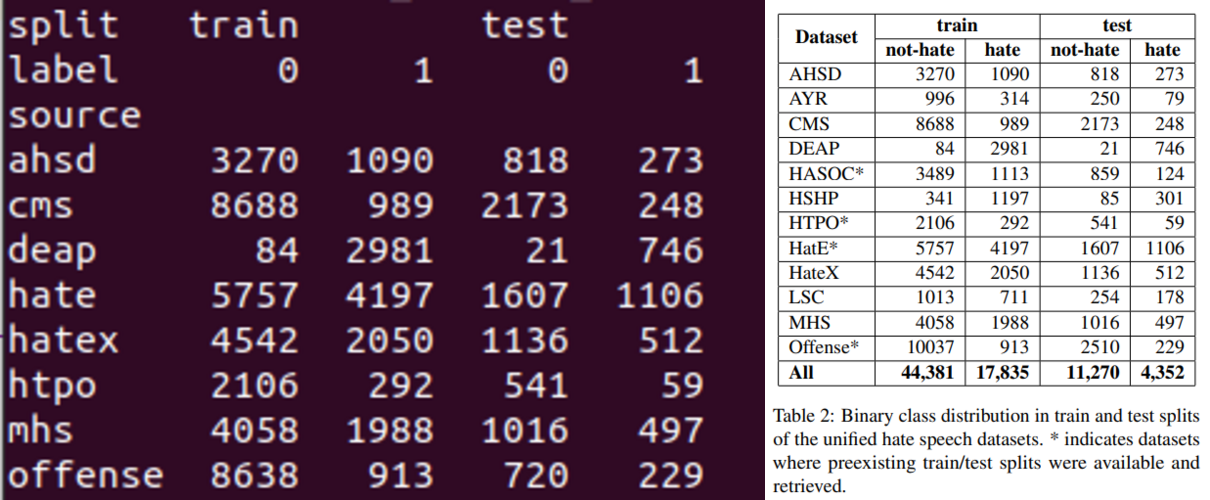
The authors manually select and unify 13 hate speech datasets for binary and multi-class classification settings. The authors do not provide the rationale on why they choose these 13 datasets.
For the multi-class classification setting, the authors devise 7 classes: racism, sexism, disability, sexual orientation, religion, other, and non-hate. This category is similar to yet smaller than the MHS dataset, including gender, race, sexuality, religion, origin, politics, age, and disability (see [1]).
For all 13 datasets, the authors apply a 7:1:2 ratio of data splitting; they also create a small external test set (i.e., Indep). With test sets kept untouched, the authors consider 3 ways of preparing data:
- Training on the single dataset.
- Training on an aggregation of 13 datasets.
- Training on a sampled dataset from the aggregation in 2. Specifically, the authors (1) find the dataset size that leads to the highest score in 1, (2) sample the dataset proportionally by the each of 13 datasets’ sizes and the the ratio of hate versus non-hate to exactly 1:1.
The processed datasets are not provided by the authors. We need to follow the guides below to obtain them; the index of the datasets is kept consistent with the HuggingFace model hub and and main paper’s Table 1.
The following are the papers that correspond to the list of datasets:
- SemEval-2019 Task 5: Multilingual Detection of Hate Speech Against Immigrants and Women in Twitter (Basile et al., SemEval 2019)
- The Measuring Hate Speech Corpus: Leveraging Rasch Measurement Theory for Data Perspectivism (Sachdeva et al., NLPerspectives 2022)
- Detecting East Asian Prejudice on Social Media (Vidgen et al., ALW 2020)
- [2004.12764] “Call me sexist, but…”: Revisiting Sexism Detection Using Psychological Scales and Adversarial Samples (Samory et al.)
- Predicting the Type and Target of Offensive Posts in Social Media (Zampieri et al., NAACL 2019)
- [2012.10289] HateXplain: A Benchmark Dataset for Explainable Hate Speech Detection (Mathew et al.)
- [1802.00393] Large Scale Crowdsourcing and Characterization of Twitter Abusive Behavior (Founta et al.)
- Multilingual and Multi-Aspect Hate Speech Analysis (Ousidhoum et al., EMNLP-IJCNLP 2019)
- [2108.05927] Overview of the HASOC track at FIRE 2020: Hate Speech and Offensive Content Identification in Indo-European Languages (Mandal et al.)
- Are You a Racist or Am I Seeing Things? Annotator Influence on Hate Speech Detection on Twitter (Waseem, NLP+CSS 2016)
- [1703.04009] Automated Hate Speech Detection and the Problem of Offensive Language (Davidson et al.)
- Hate Towards the Political Opponent: A Twitter Corpus Study of the 2020 US Elections on the Basis of Offensive Speech and Stance Detection (Grimminger & Klinger, WASSA 2021)
- Hateful Symbols or Hateful People? Predictive Features for Hate Speech Detection on Twitter (Waseem & Hovy, NAACL 2016)
Despite the availability of the sources, it is quite hard to reproduce the original dataset as (1) many of the datasets in the table do not come with the predefiend splits; the only datasets that are available and have such splits are HatE, HatX, and HTPO, (2) how the authors unify (for example, deriving binary label from potentially complicated provided labels) the datasets is unknown, and (3) how the authors process the texts is also unknown.
It is better to find a model whose checkpoints and exact training datasets are both available; one such example is the Alpaca language model.
Models and Fine-Tuning
The authors start from the bert-base-uncased, roberta-base, and two models specifically customized to Twitter (see [2], [3]). The authors carry out the HPO on learning rates, warmup rates, number of epochs, and batch size using hyperopt.
Experiments
-
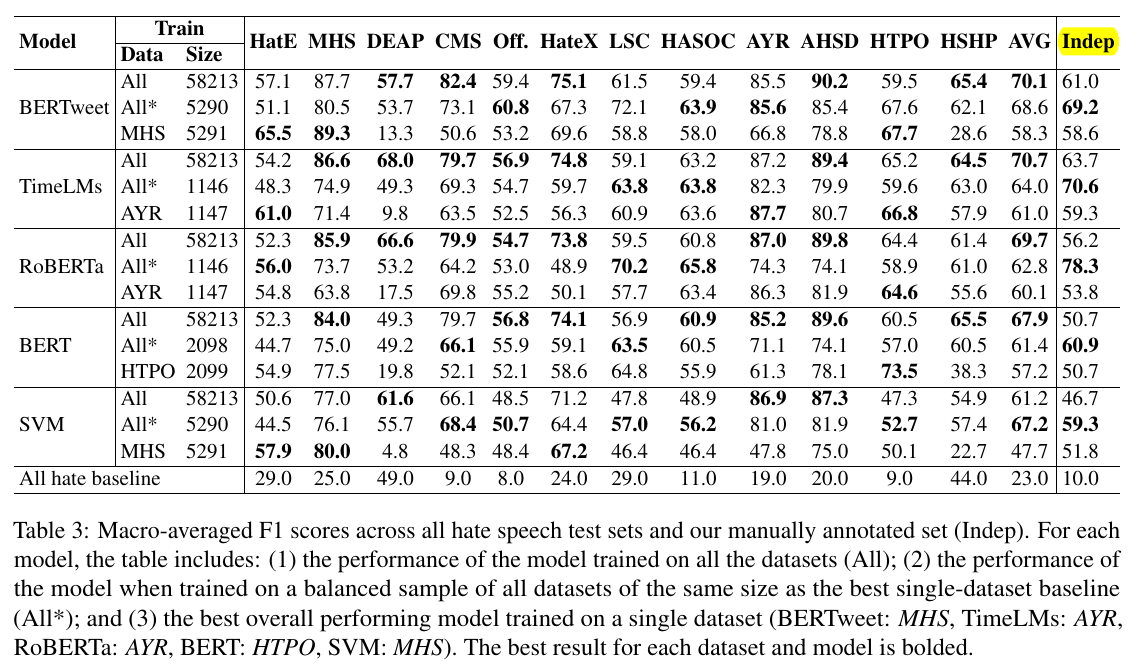
The data preparation method 3 (
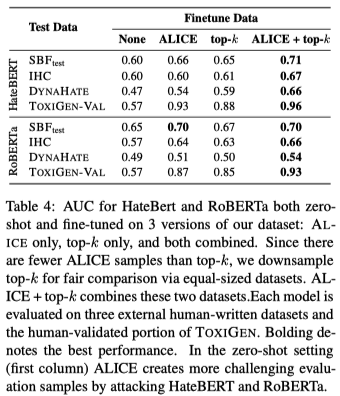
All*) performs better than the method 1 (MHS, AYR, etc). It also achieves the highest scores on the Indep test set (Table 3).
Other Information
- Language classification tasks could be done with
fasttext models (doc).
Comments
-
Ill-Defined Data Collection Goal
We can read the sentence like following from the paper:
- For example both CMS and AYR datasets deal with sexism but the models trained only on CMS perform poorly when evaluated on AYR (e.g. BERTweetCSM achieves 87% F1 on CSM, but only 52% on AYR).
- This may be due to the scope of the dataset, dealing with East Asian Prejudice during the COVID-19 pandemic, which is probably not well captured in the rest of the datasets.
The issue is that there is not quantitative measure of the underlying theme of a dataset (for example, CMS and AYR). The dataset curators may have some general ideas on what the dataset should be about; they often do not have a clearly defined measure to quantify how much one sample aligns with their data collection goals.
I wish to see some quantitative measures on topics and distributions of an NLP dataset.
Reference
- Targeted Identity Group Prediction in Hate Speech Corpora (Sachdeva et al., WOAH 2022)
- BERTweet: A pre-trained language model for English Tweets (Nguyen et al., EMNLP 2020)
- TimeLMs: Diachronic Language Models from Twitter (Loureiro et al., ACL 2022): This paper also comes from Cardiff NLP. It considers the time axis of the language modeling through continual learning. It tries to achieve OOD generalization (in terms of time) without degrading the performance on the static benchmark.