[Semantic Scholar] – [Code] – [Tweet] – [Video] – [Website] – [Slide] – [Poster]
Change Logs:
- 2023-10-06: First draft. The paper appears at ACL 2023.
Method
The cycle training has two models involved: a data-to-text model \mathcal{M} _ \text{D2T} and a text-to-data model \mathcal{M} _ \text{T2D}; they are both initialized as `google/t5-base; this base model empirically shows an edge in the WebNLG 2020 competition for RDF-to-text generation.
The proposed approach is similar to self-training in the text-generation domain. Specifically, there are three datasets: paired texts and data, unpaired data D and unpaired texts T.
- Initialization: Fine-tuning \mathcal{M} _ \text{D2T} and \mathcal{M} _ \text{T2D} using the paired dataset; the data is converted into linearized triplets.
- Repeating the following for multiple epochs: the number of epochs in the paper is set to 50. At epoch k, we do the following:
- Generating text \hat{T} =\mathcal{M} _ \text{D2T} ^ {(k-1)}(D) and data \hat{D}=\mathcal{M} _ \text{T2D} ^ {(k-1)}(T) with models from epoch (k-1).
- Fine-tuning models with pseudo pairs (D, \hat{T}) and (\hat{D}, T). Specifically, we do the following:
- $\mathcal{M} _ \text{D2T} ^{(k)} \leftarrow \mathrm{FineTune}(\mathcal{M} _ \text{D2T} ^{(k-1)}, (\hat{D}, T))$; this step tries to reconstruct texts $T$ from intermediate $\hat{D}$.
- $\mathcal{M} _ \text{T2D} ^{(k)} \leftarrow \mathrm{FineTune}(\mathcal{M} _ \text{T2D} ^{(k-1)}, (D, \hat{T}))$; this step tries to reconstruct data $D$ from intermediate $\hat{T}$.
Note that the difference between this scheme and self-training is that we use the labels inferred from the model to train itself in self-training. However, we do not use the generated pairs (D, \hat{T}) from \mathcal{M} _ \text{D2T} to fine-tune itself; rather, we leverage a second model \mathcal{M} _ \text{T2D} to generate the training data for \mathcal{M} _ \text{D2T}.
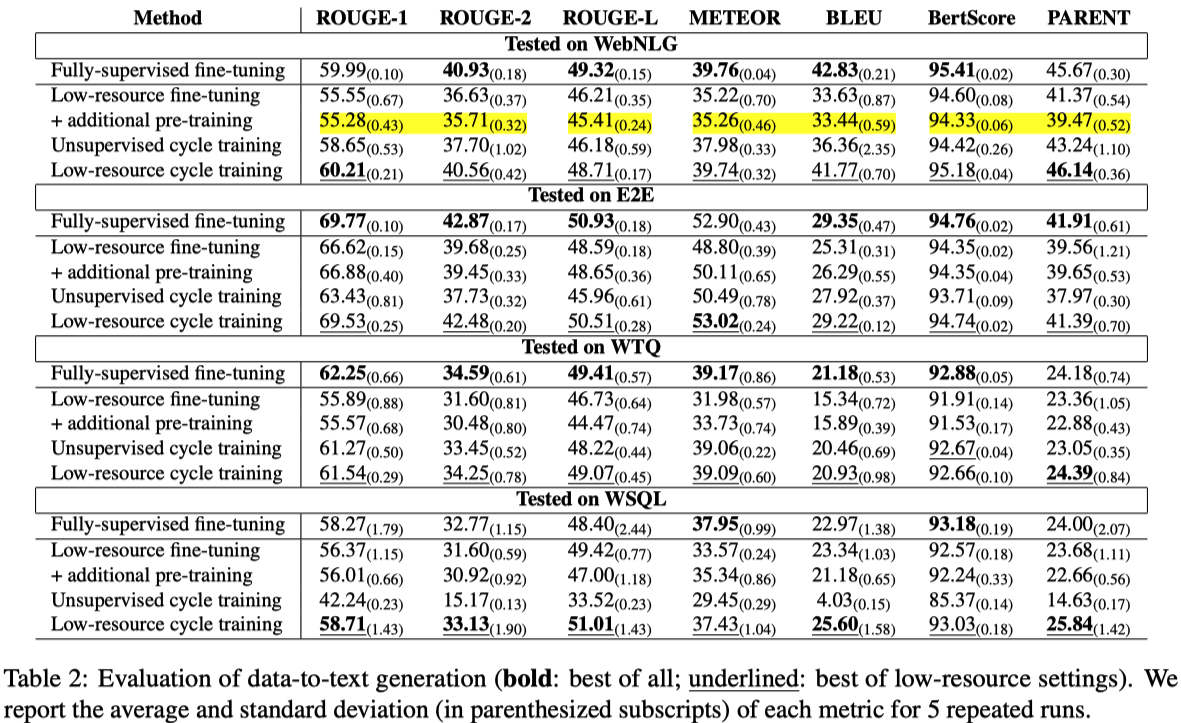
From the experiment results, we could see:
- The low-resource cycle training has strong performance on par with full-scale fine-tuning.
- The small set of paired texts is important: the low-resource setting consistently outperforms the unsupervised setting.
- Pretraining does not help much if the paired datasets are of small scale.
Additional Notes
-
Prerequisite
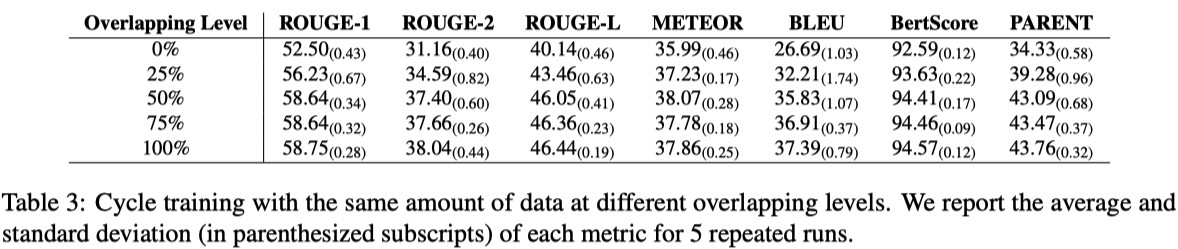
The unpaired data and text corpus should have at least 50% overlap in terms of entities to obtain a reasonable level of faithfulness.
-
Automatic Faithfulness Evaluation
The PARENT metric [1] used in this work highly correlates with human annotations; this metric is specially designed for table-to-text tasks.
Reference
- Handling Divergent Reference Texts when Evaluating Table-to-Text Generation (Dhingra et al., ACL 2019)