[Semantic Scholar] – [Code] – [Tweet] – [Video] – [Website] – [Slide]
Change Log
- 2023-12-05: First draft.
Overview
The authors propose a method to automatically generate a balanced dataset (13 identity groups and both toxic and benign) of 14K (using ALICE) + 260K (using demonstraionts) = 274K samples without explicit words based on the following two observations:
- It is hard to collect hard toxic content to augment the training set of machine learning models as overly toxic content often co-occur with small set of explicit words.
- Furthermore, the explicit mention (for example, Muslim) of language styles (for example, African-American English) of some identity groups are unfairly classified as toxic by existing models.
Method
ALICE
The authors incoporate a binary hate speech classifier’s score on the “hate” or “non-hate” class into the decoding process to encourge more hateful or more non-hateful generation given a prompt.
Originally, the hateful prompt will lead to hateful continuation. However, when we have the classifier in the loop, the continuation’s hatefulness will be mitigated yet not reversed, leading to implicit hate speech (i.e., hard toxic content).
Demonstration
Another method the authors propose is manually collecting implicit hate speech from the web, and then demonstrate to obtain more texts from GPT-3. This effort lead to 260K samples.
Experiments
-
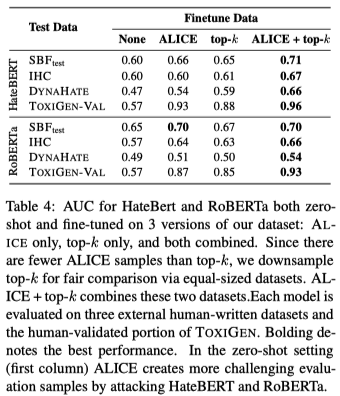
Data Augmentation with ToxiGen Improves Accuracy on OOD Test Sets
The authors further fine-tune HateBERT and ToxDectRoBERTa using the collected dataset and test it on
social_bias_frames,SALT-NLP/ImplicitHate, andaps/dynahate. The authors observe improved accuracy after fine-tuning.