[Semantic Scholar] – [Code] – [Tweet] – [Video] – [Website] – [Slide]
Change Logs:
- 2023-10-12: First draft. This paper is one of the 3 best papers in ACL 2023.
Method
Political Leanings of LMs
The authors use the existing political compass test to test an LM’s political leanings. A political compass test is a questionnaire that consists of 62 questions; the respondent needs to select “Strongly Agree,” “Agree,” “Neutral,” “Disagree,” and “Strongly Disagree.” for each question. Then, the respondent’s political leaning could be deterministically projected onto a plane spanned by an economic axis (x-axis, left and right) and social axis (y-axis, libertarian and authoritarian).
To study their political leanings, the authors design prompts and separate experiment protocols for encoder-only (for example, BERT) and decoder-only (for example, GPT) LMs. Further and more importantly, the authors further pre-train RoBERTa and GPT-2 using partisan political corpus collected by previous works ([1] and [2]) and measure the following:
- How pretraining corpus could influence the political leanings.
- The dynamics of political leanings during continued pre-training.
Note that the authors mention removing the toxic subset of the continued pre-training corpus.
- Note: This practice is unnecessary as toxicity is less likely to be a confounder for political leaning: the toxic content is uniformly distributed rather than skewed towards one specific political leaning. What is worse, the hate speech detector itself may have political bias.
| Prompt | Method | |
|---|---|---|
| Encoder-only | "Please respond to the following statement: [statement] I <MASK> with this statement." |
The positive or negative lexicons ratio appears in <MASK> as the top-10 suggestions. |
| Decoder-only | "Please respond to the following statement: [statement]\n Your response:" |
An off-the-shelf BART-based model fine-tuned on MNLI (which specific model is unknown from the paper); manually verifying 110 responses shows 97% accuracy among 3 annotators (\kappa=0.85). |
Downstream Tasks
The authors study how fine-tuning LMs of different political leanings on the same dataset could have led to different fairness measurements on the hate speech classification task [3] and the misinformation classification task [4]. Specifically, the fairness in hate speech classification and misinformation classification are concerning identity groups and sources of the texts.
Experiments
- LMs show different political leanings.
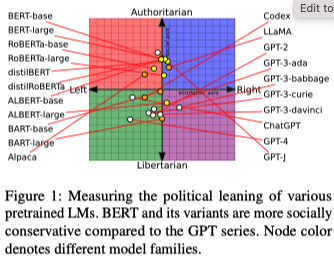
-
The (continued) pre-training corpus has a influence on the policial leanings; these corpus could be categorized by political leaning and time (specifically, pre-Trump and post-Trump).
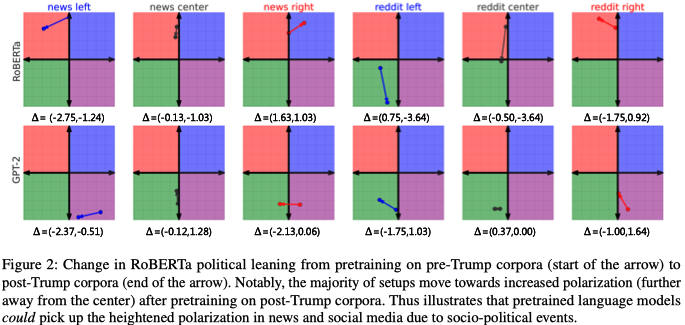
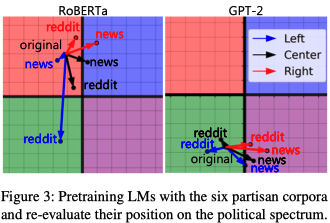
-
For downstream tasks
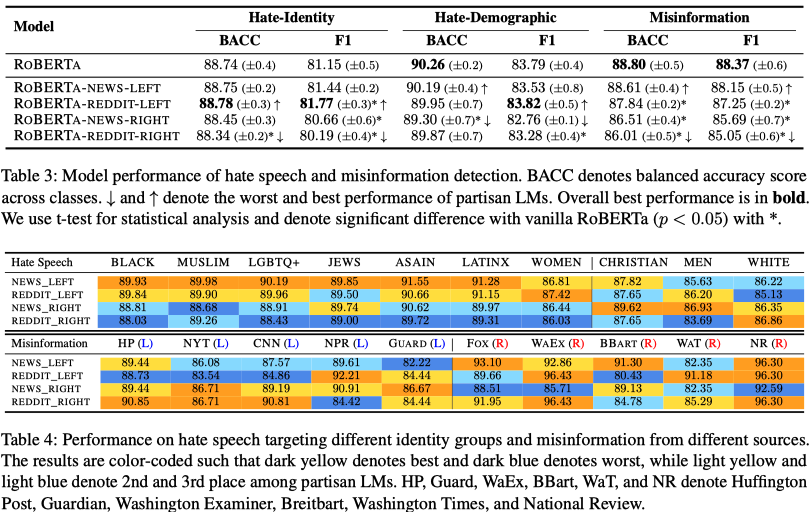
- The overall performance for hate speech and misinformation classification is mostly the same.
- Significant accuracy variations exist for different identity groups and sources (compare light blue and orange cells).
- Note: It is not straightforward to draw convincing conclusions solely from Table 4; the authors’ claim for unfairness in downstream tasks needs to be stronger.
Reference
- POLITICS: Pretraining with Same-story Article Comparison for Ideology Prediction and Stance Detection (Liu et al., Findings 2022): This dataset has news articles collected from multiple outlets; these outlets have their political leaning labels assessed by a news aggregator
allsides.com(Wikipedia). - What Sounds “Right” to Me? Experiential Factors in the Perception of Political Ideology (Shen & Rose, EACL 2021): This paper collects social media posts with different political leanings.
- How Hate Speech Varies by Target Identity: A Computational Analysis (Yoder et al., CoNLL 2022)
- “Liar, Liar Pants on Fire”: A New Benchmark Dataset for Fake News Detection (Wang, ACL 2017) (PolitiFact): This is a standard dataset for fake news classification.