Contents
Overview
The edited knowledge in this paper is in the form of triplets. Given the prompt Eiffel Tower is located in the city of, the original model will output Paris as expected. However, after model editing, the output could be other tokens with high probability. For example, Seattle.
Suppose we have an input x and its original output is y := \mathcal{M}(x), if we apply some intervention to \mathcal{M}(\cdot) and expect the future output to be y’, we require the editing to be reliable, local, and general:
- Reliable: The edited model should output y’ with a high probability.
- Local: The output of anything semantically different from x should not change.
- General (or Consistent): The output of anything semantically equivalent to x should also change.
The community seems to focus on editing encoder-decoder models or decoder-only models ([12] and [13]) due to their ability to generate texts. However, the encoder-only models are less of interest even though MEND and TransformerPatcher both study it. For example, the paper [13] mentions the following:
<
blockquote>
Previous studies typically used smaller language models (<1B) and demonstrated the effectiveness of current editing methods on smaller models like BERT (Devlin et al., 2019). However, whether these methods work for larger models is still unexplored. Hence, considering theHowever, whether these methods work for larger models is still unexplored. Hence, considering the editing task and future developments, we focus on generation based models and choose larger ones: T5-XL (3B) and GPT-J (6B), representing both encoder-decoder and decoder-only structures.
The editing methods could be compared on whether the model parameters have been modified. There are several scenarios:
- Model Parameters are Unchanged
- Model Parameters are Unchanged, but there are Additional Parameters
- Model Parameters are Changed: This could be done using either (1) locating-and-editing, or (2) meta-learning with a separate hypernetwork.
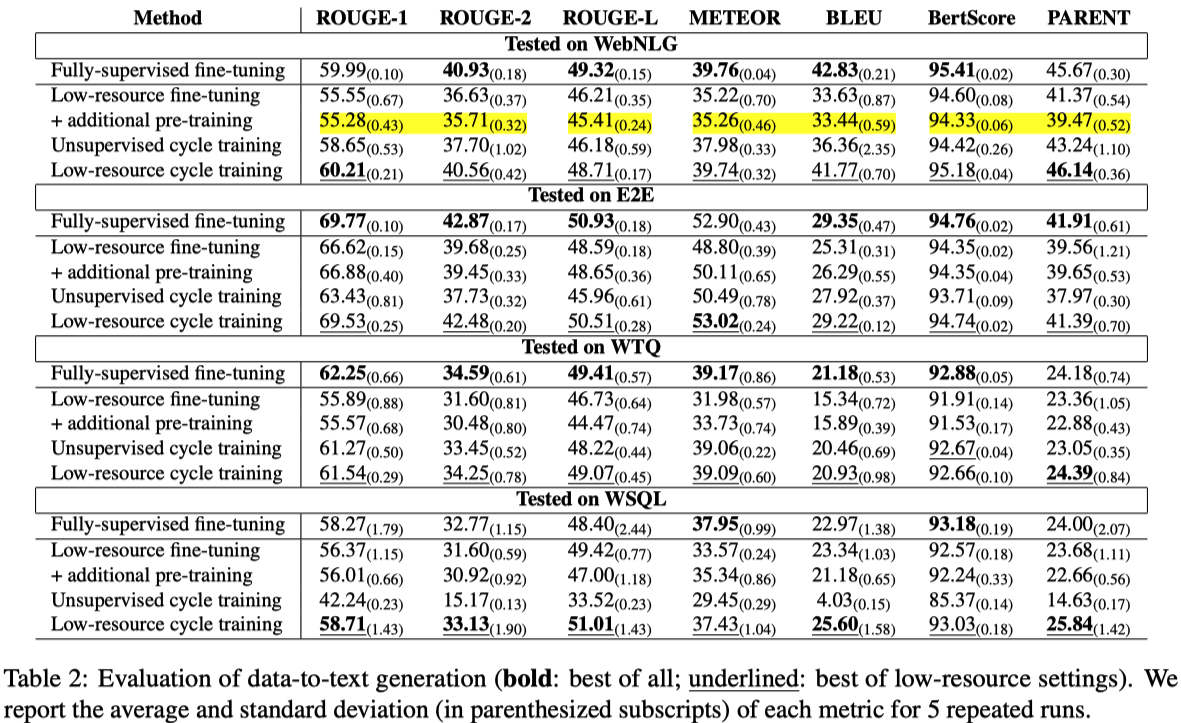
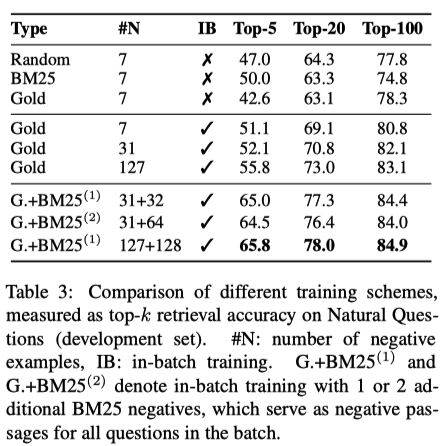
| Method | Category | Note |
|---|---|---|
| ENN | 3 | |
| KnowledgeEditor | 3 | |
| MEND | 3 | |
| SEARC | 1 | |
| ROME | 3 | |
| MEMIT | 3 | |
| TransformerPatcher | 2 | |
| KnowledgeNeuron | 3 | |
| MQuAKE | 1 | |
| IKE | 1 | |
| MemPrompt | 1 |
ROME
KnowledgeNeuron
KnowledgeEditor
MEND
TransformerPatcher
MEMIT
Experiments
Datasets
The canonical tasks of model editing includes fact-checking on FEVER and QA with the zsRE datasets.
- For FEVER, the editing dataset is based on the original input and flipped label.
- For zsRE, the editing dataset is based on the original input and an answer that is not top-1.
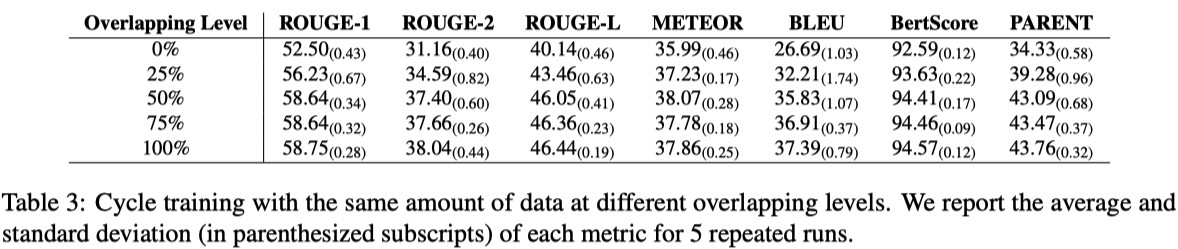
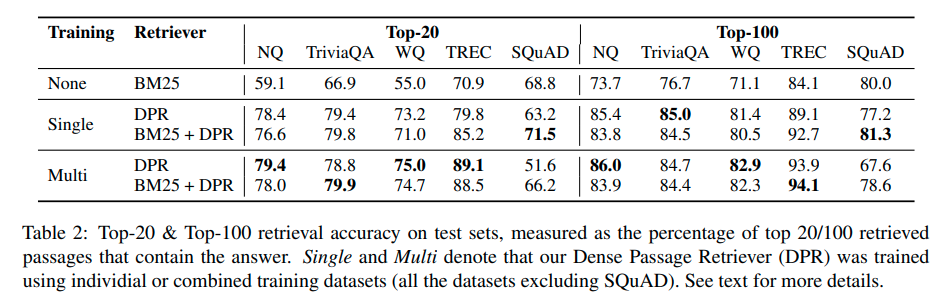
| Paper | Fact Checking | QA | Generation | Note |
|---|---|---|---|---|
| MEMIT [1] | N/A | zsRE and CounterFact | N/A | There are two intermediate works ROME and SEARC. But they are omitted as the best model is MEMIT. |
| MEND [5] | Binary FEVER | zsRE | Wikitext | The first two tasks are chosen same as De Cao et al.; Wikitext is an additional dataset. |
| KnowledgeEditor [4] | Binary FEVER | zsRE | N/A | |
| Constrained Fine-Tuning [3] | N/A | zsRE and T-REx | N/A | |
| ENN [4] | N/A | N/A | N/A | This early work experiments on CIFAR-10 and MT tasks. |
Additional Notes
- The RDF triplet may be the most unambiguous way to express instances of a specification; it is a classical way to represent knowledge and could be bidirectionally converted from and to a SQL database (Wikipedia).
- The overarching research field is called “mechanistic interpretibility.”
- Knowledge editing is thought to be difficult because now knowledge is stored distributionally rather than symbols. However, the paper [2] finds that the localization is quite concentrated in MLPs; the authors focus on MLPs because they believe the attention is too complicated to study.
- MLPs are storing information while attention is gathering information: the information “Seattle” is in one specific location of GPT-2 before the “the space needle is located at” is asked.
- Model editing is different from adversarial attack since the former tries to change the model while the latter tries to change the input data. However, model editing could have dual use beyond model patching: engineering an LM that always generates non-factual content.
- One limitation of the model editing is that we could only update singleton facts; we could not update the higher level content, for example, specifications and political leanings.
Reference
Kevin Meng and David Bau have published a series of works ([1] and [2]) on knowledge editing for transformers. [3] through [6] are the predecessors to the proposed work; they could at most scale to 75 edits.
- [2210.07229] Mass-Editing Memory in a Transformer (MEMIT system).
- [2202.05262] Locating and Editing Factual Associations in GPT (ROME system).
-
[2012.00363] Modifying Memories in Transformer Models: This paper is the first to study the problem of fact editing transformers. The authors propose to fine-tune the models’ first and last transformer block on the modified facts \mathcal{D} _ M while constraining the parameter within a small space.
\min _ {\theta \in \Theta} \frac{1}{m} \sum _ {x \in \mathcal{D}_M} L(x;\theta)\quad s.t. \Vert \theta – \theta_0 \Vert \leq \delta -
[2004.00345] Editable Neural Networks (Sinitsin et al., ICLR 2020) (ENN system): This paper is the first to apply meta-learning to model editing; it is a precursor to follow-up works [5], [6], and [7]. Besides, it mentions the following important observations:
- The goal of model editing is quickly patching critical mistakes made by a neural model. The problem precludes (1) retraining with augmented dataset because it is slow, and (2) manual cache as it does not adapt to diverse input changes.
-
Editing Factual Knowledge in Language Models (De Cao et al., EMNLP 2021) (KnowledgeEditor system): The authors observe that the previous methods [3] and [4] have following limitations in their edited models:
- Unreliable Edits: For sentences that are different from x, the behaviors should not have changed.
- Inconsistent Edits: For sentences that are semantically equivalent to x, the behaviors should have changed.
Furthermore, the method [4] also requires expensive retraining.
- [2110.11309] Fast Model Editing at Scale (Mitchell et al.) (MEND system): This paper improves the De Cao et al. in editing models with a scale of 10B parameter. On smaller models, the ENN model is better than KnowledgeEditor. The code base of this work also implements ENN and KnowledgeEditor for comparison.
- [2206.06520] Memory-Based Model Editing at Scale (Mitchell et al.) (SEARC system): The authors do not release code for SEARC.
- Transformer Feed-Forward Layers Are Key-Value Memories (Geva et al., EMNLP 2021): This paper helps the main paper constrain the editing target to the MLP layers.
- Knowledge Neurons in Pretrained Transformers (Dai et al., ACL 2022) (KnowledgeNeuron system)
- [2305.12740] Can We Edit Factual Knowledge by In-Context Learning? (Zhang et al.)
- [2301.09785] Transformer-Patcher: One Mistake worth One Neuron (Huang et al., ICLR 2023): This paper proposes to add one neuron in the last FFN layer and activates this neuron when the exact same error is seen again; this error will be corrected; their experiments include both an encoder-only model (BERT) and an encoder-decoder model (BART).
- [2308.07269] EasyEdit: An Easy-to-use Knowledge Editing Framework for Large Language Models (Wang et al.)
-
[2305.13172] Editing Large Language Models: Problems, Methods, and Opportunities (Yao et al., EMNLP 2023): This paper, together with the above paper introducing
easyeditlibrary, provides comprehensive survey and Python library for knowledge editing. We could stick to these papers and only read original papers when necessary. - From Pretraining Data to Language Models to Downstream Tasks: Tracking the Trails of Political Biases Leading to Unfair NLP Models (Feng et al., ACL 2023)
- [2305.14795] MQuAKE: Assessing Knowledge Editing in Language Models via Multi-Hop Questions (Zhong et al.)
- Memory-assisted prompt editing to improve GPT-3 after deployment (Madaan et al., EMNLP 2022)
The following are other useful references:
- semantic web – Translating a complex Sentence into set of SPO triple (RDF) (maybe with reification) – Stack Overflow: The user notes that it is difficult to convert the natural language into a standard structure in a definitive way. Some of the approximations include dependency parsing, constituency parsing, knowledge graph, and First-Order Logic (FOL).
- ROME: Locating and Editing Factual Associations in GPT (Paper Explained & Author Interview) – YouTube