[Semantic Scholar] – [Code] – [Tweet] – [Video] – [Website] – [Slide]
Change Logs:
- 2023-10-06: First draft. This paper appears at NeurIPS 2020.
Method
Given a query x, the RAG system first retrieves z from traditional index (for example, Wikipedia) based on a DPR model p _ \eta(z \vert x). Then the generator generates answers in the free text form through p _ \theta (y _i \vert x, z, y _ {1:i-1}), where y _ {1:i-1} is a prompt. In this process, the z is a latent variable that is not observable by the users.
- Note: The ability to generate answer in the free-text form is impressive because many of the experimented tasks are extractive.
The RAG system could be trained jointly on p _ \eta and p _ \theta as it is end-to-end differentiable. The authors provide two variants of the RAG system:
- RAG-Sequence: For a query, the entire output sequence is conditioned on the same document.
-
RAG-Token: For a query, each token in the output sequence could be conditioned on the different documents. The authors note that the RAG could be used for knowledge-intensive tagging task:
Finally, we note that RAG can be used for sequence classification tasks by considering the target class as a target sequence of length one, in which case RAG-Sequence and RAG-Token are equivalent.
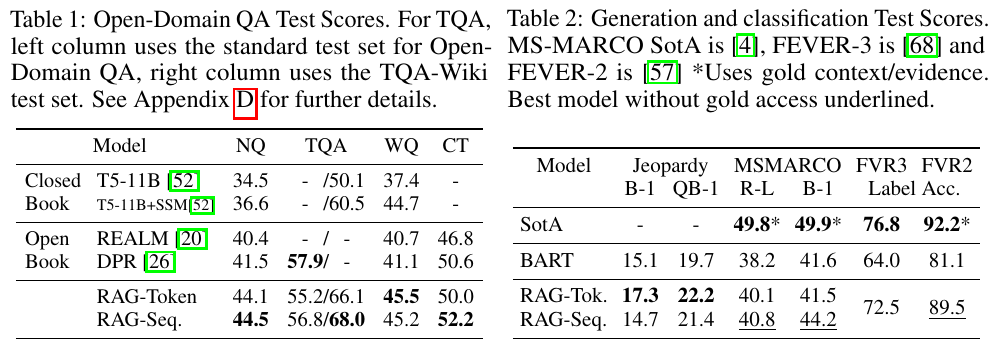
Note that RAG-Token does not seem to much better than RAG-Sequence but the former has much more downloads on HuggingFace.
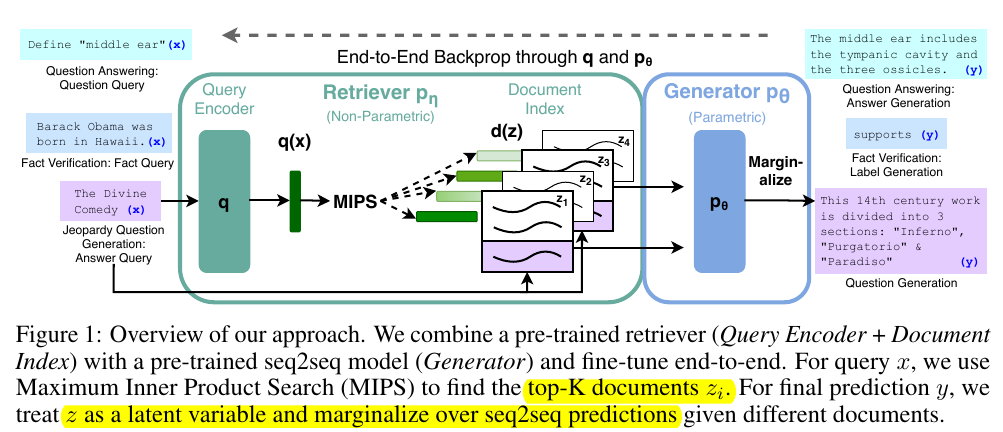
Specifically, the retrieval model is based on bert-base-uncased and the generator is based on facebook/bart-large. Importantly, to accelerate the training, document encoder is frozen and gradients only travel to the query encoder; this design choice does not hurt performance.
Additional Notes
- The benefits of RAG is that the index could be updated on demand (“hot-swapping” in the paper).